Open any AI newsletter this week. Read the headlines. Count the names. Claude, GPT, Gemini, maybe a mention of Grok or Llama. The conversation orbits the same handful of frontier labs, the same benchmark announcements, the same race to the top of some intelligence leaderboard.
That conversation is reasonable if you are tracking the research frontier. It is misleading if you are trying to understand which AI models actually run in production. Because when you look at the most-used AI models by real usage, the famous names are not where you expect them to be.
A quick note on where this comes from before we dig in. Everything below is based on what I personally pulled from the OpenRouter rankings and apps pages one evening this week, not from some global census of AI usage everywhere. I exported the live data from OpenRouter’s rankings and apps pages and went through it line by line. OpenRouter is not a small sample. It routes traffic for millions of developers across hundreds of models from more than 60 providers, and it settles roughly 33 trillion tokens every week. It is one of the most honest windows we have into what developers choose when the choice is genuinely theirs, unmediated by a vendor contract or a procurement committee.
What the data shows contradicts almost every AI conversation I have with enterprise leaders.
The AI model leaderboard nobody is publishing
Here are the top 10 most-used AI models on OpenRouter by weekly token volume, as of late June 2026.
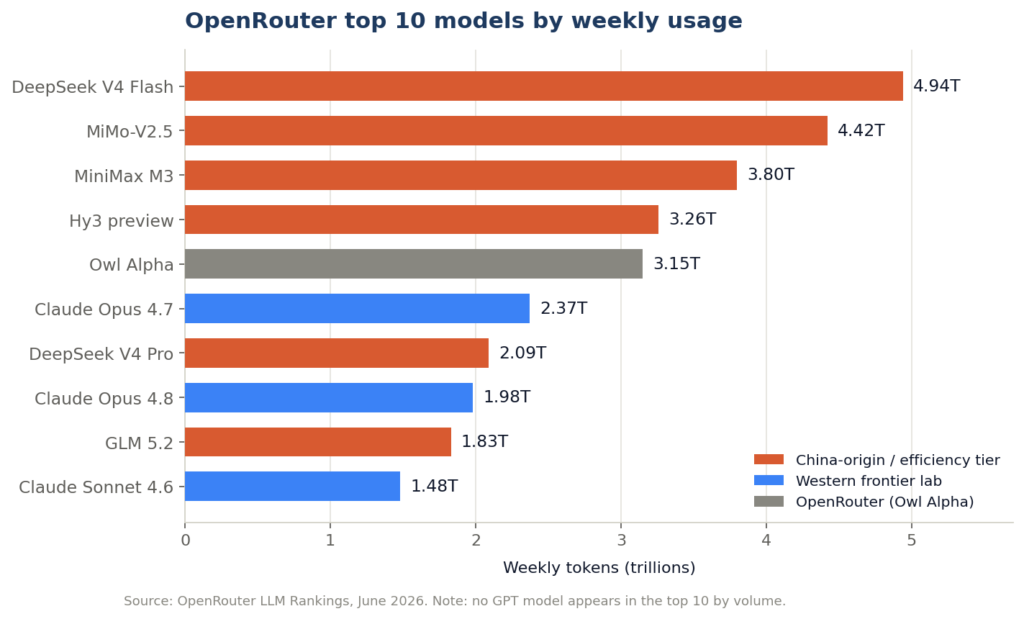
Top 10 AI Models on Open Router | June 2026
| Rank | Model | Provider | Weekly tokens | Week change |
|---|---|---|---|---|
| 1 | DeepSeek V4 Flash | DeepSeek | 4.94T | +8% |
| 2 | MiMo-V2.5 | Xiaomi | 4.42T | +16% |
| 3 | MiniMax M3 | MiniMax | 3.80T | -14% |
| 4 | Hy3 preview | Tencent | 3.26T | -10% |
| 5 | Owl Alpha | OpenRouter | 3.15T | +32% |
| 6 | Claude Opus 4.7 | Anthropic | 2.37T | -21% |
| 7 | DeepSeek V4 Pro | DeepSeek | 2.09T | -11% |
| 8 | Claude Opus 4.8 | Anthropic | 1.98T | +47% |
| 9 | GLM 5.2 | Z.ai | 1.83T | +209% |
| 10 | Claude Sonnet 4.6 | Anthropic | 1.48T | -9% |
Sit with that for a second.
The number one model is DeepSeek V4 Flash. Not their flagship reasoning model. Their efficiency-optimized Flash variant. The fast, cheap one. It is processing nearly 5 trillion tokens a week, more than double what Claude Sonnet 4.6 handles down at number ten.
A smartphone company, Xiaomi, holds the number two spot.
The first model from a frontier lab that the entire industry obsesses over does not show up until number six.
And here is the detail that stopped me: there is no GPT model in the top 10 at all. OpenAI, the company whose name is synonymous with this technology in the public imagination, does not place a single model in the most-used list by volume. Not one.
This is not a fluke week. It is structure.
No single AI provider owns this market
The other thing the export makes obvious is how fragmented the AI model market has become. Here is the share of weekly token volume by model author.
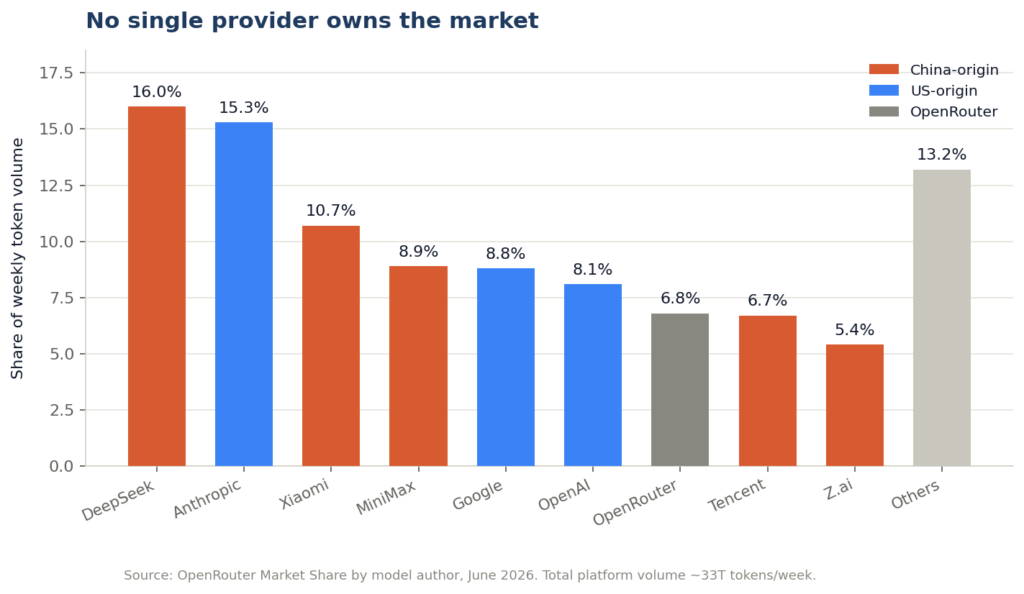
| Provider | Share of weekly tokens |
|---|---|
| DeepSeek | 16.0% |
| Anthropic | 15.3% |
| Xiaomi | 10.7% |
| MiniMax | 8.9% |
| 8.8% | |
| OpenAI | 8.1% |
| OpenRouter | 6.8% |
| Tencent | 6.7% |
| Z.ai | 5.4% |
| Others | 13.2% |
The leader holds 16 percent. Six different providers sit between 8 and 16 percent. This is not a market with a king. It is a market with a dozen credible options, and the gap between the biggest and the sixth-biggest is about eight percentage points.
Compare that to the mental model most enterprise leaders carry, where the entire decision collapses to “Claude or GPT?” The developers actually shipping have moved on from that framing. They are routing across a far wider field of AI models, and they are doing it deliberately.
Smarter does not mean more used
This is the finding that should make any procurement team uncomfortable.
OpenRouter publishes an intelligence benchmark alongside the usage data. When you plot one against the other, the relationship is close to inverted.
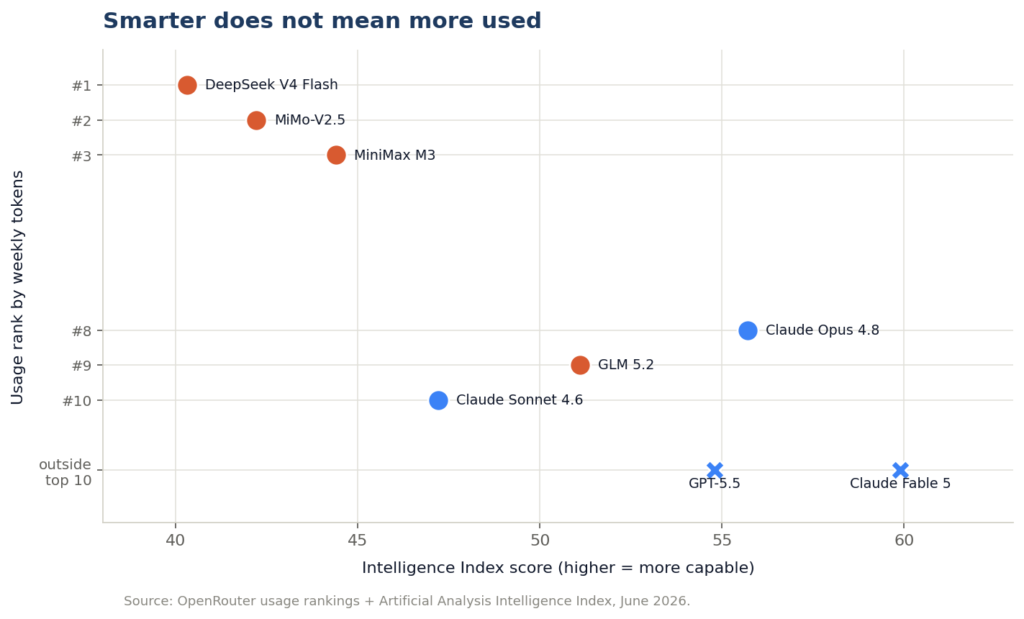
The most capable model on the platform by intelligence score is Claude Fable 5, at 59.9. It sits as a lonely dot on the far right of OpenRouter’s price chart, near 10 dollars per million tokens, and it does not appear anywhere in the usage top 10. Claude Opus 4.8 and GPT-5.5, the next most intelligent, are similarly thin on volume.
Meanwhile the most-used AI model on the entire platform, DeepSeek V4 Flash, scores around 40 on that same intelligence index. That is roughly two-thirds of the top score. MiMo-V2.5, sitting at number two by usage, scores 42.
So the model that wins the volume war delivers about 70 percent of the intelligence of the smartest model available, at a fraction of the price, and the market picks it overwhelmingly.
The reason is not that developers cannot tell the difference. It is that for most work, the difference does not justify the cost. Production teams optimize for inference cost, latency, tool-call reliability, and context economics. They do not optimize for marginal gains on a static benchmark that gets reshuffled every quarter. Benchmarks can be tuned. Routed tokens cannot. Weekly token volume is the closest thing we have to a thermometer for what AI is actually worth in practice.
Where frontier AI models still win
This is the part that keeps the picture honest. The frontier premium is real, it is just narrow.
OpenRouter breaks spend down by task type: General work is 35.7 percent of spend, Agent workflows 30.4 percent, Code 26.5 percent, and Data 7.5 percent. When you drill into the harder reasoning categories, the picture flips back toward the frontier labs. In the Classification category, Claude Sonnet 4.6 and Claude Opus 4.7 lead at 13.5 percent of spend each, with GPT-5.5 third at 11.6 percent. The cost-efficient models that dominate raw volume recede here.
That is the market telling you two things at once. For high-stakes reasoning, for trust-sensitive output, for the cases where a wrong answer is expensive, teams pay the premium for frontier intelligence on purpose. For everything else, which is most of the tokens, they reach for the cheap, fast, good-enough model without hesitation.
The most popular AI apps tell the same story
If the model rankings surprise you, the apps rankings should reframe how you think about AI adoption entirely.
The single most popular application on OpenRouter is Hermes Agent, an open-source self-improving agent from Nous Research. The top of the chart is almost entirely agents and coding tools: Hermes Agent, Kilo Code, Claude Code, OpenClaw, then a coding agent called pi, then Cline. Cursor, the tool that gets the most press of any of them, sits at number 14 by token volume.
There is also a large category that essentially never appears in enterprise AI discussions. Entertainment and roleplay applications like Janitor AI, ISEKAI ZERO, SillyTavern, and HammerAI move serious volume. The broader OpenRouter usage studies have found that creative roleplay accounts for more than half of all open-source model usage (OpenRouter and a16z State of AI report). It is not a niche. For open models, it is the plurality use case, and it is invisible from inside the enterprise bubble.
Strip out entertainment, and what remains is overwhelmingly developer work. Coding and agentic workflows together are the majority of serious AI usage. If your AI strategy does not have a strong engineering and agent-orchestration component, you are optimizing for the visible surface of AI adoption and missing the structural substrate underneath it.
What to learn from this if you are getting into AI
Whether you are entering as a practitioner or evaluating AI as a buyer, the OpenRouter data points to a few conclusions worth building into your thinking now, rather than discovering them through an expensive infrastructure bill later.
First, model selection is a per-workload decision, not a platform decision. “Which AI model should we use?” is the wrong question. The right question is “which model for this task, at this volume, with these latency and quality constraints?” High-volume general chat, agentic loops, internal tooling, and trust-sensitive customer-facing output do not belong on the same model. The teams running efficient AI infrastructure maintain a tiered routing strategy, matching each workload to the cheapest model that clears the quality bar for that specific job.
Second, the Chinese and open-weight ecosystem is a production-grade option, not a research curiosity. DeepSeek, MiMo, MiniMax, GLM, and Kimi are running at multi-trillion-token weekly volumes in real developer environments. If your evaluation shortlist contains only the two or three Western frontier names you already recognized, you are leaving meaningful cost-performance on the table for reasons of brand familiarity rather than evidence.
Third, learn agents and developer tooling, not just chat. The highest-volume, fastest-growing, most structurally important AI usage is happening in coding agents and orchestration tools. That is where the demand is, and that is where the skills compound.
Fourth, treat benchmark performance with suspicion as a proxy for production value. The model that tops your curated evaluation may not be the one your team reaches for six months later when costs start compounding. Build cost, latency, and tool-call reliability into your evaluation from day one, not just answer quality.
So, do you actually need Frontier AI?
The market has already answered. For the overwhelming majority of tokens flowing through real systems, no. Cost-efficient models running a few months behind the absolute frontier are not merely sufficient. They are winning decisively. For a narrow band of high-stakes reasoning work, frontier intelligence is worth paying for, and developers pay for it on purpose.
The enterprise AI market is not converging on one model or one provider. It is stratifying. Quality-track work on frontier models. Volume-track work on cost-efficient alternatives. The organizations that get the most out of AI over the next few years will be the ones who build the routing infrastructure to move workloads intelligently across that whole spectrum, instead of picking one logo and applying it to everything.
The leaderboard nobody talks about is telling you something. The most-used AI models are winning by volume because they solved the right problem. Not maximum intelligence. Maximum value at production scale.
That is not a consolation prize. That is the product.
Data source: OpenRouter LLM Rankings and App and Agent Rankings, accessed June 26, 2026. openrouter.ai/rankings and openrouter.ai/apps